Ai应用
Ai应用 Ai资讯
Ai资讯 AI生图
AI生图 AI生视频
AI生视频 AI生PPT
AI生PPT AI数字人系统
AI数字人系统
 提交您的产品
提交您的产品 PDF-Craft:一个扫描书籍PDF文件转Markdown/EPUB工具

PDF-Craft是什么?
PDF-Craft是一个用于处理PDF文件的开源项目,专注于将扫描书籍的PDF转换为Markdown或EPUB格式。它通过OCR技术识别文字,并利用ai算法提取文本、过滤页眉页脚等元素,生成结构化内容。支持本地计算和LLM辅助功能,适合学术论文、小册子及长篇书籍的格式转换。
")
PDF-Craft功能特征
格式转换:
支持将PDF转换为Markdown格式,适合论文或小书本。
超过100页的,可结合了本地OCR和云端LLM处理,生成带目录分章节的EPUB。
智能提取:
使用DocLayout-YOLO和自定义算法提取正文,过滤页眉、页脚、脚注、页码等元素。
在跨页时,算法会处理前后文的顺接问题。
OCR识别:
使用OnnxOCR进行文字识别,支持插图、表格和公式的截图,并直接插入到输出文件中。
阅读顺序优化:
通过layoutreader确定符合人类阅读习惯的顺序。
LLM辅助:
在EPUB转换过程中,通过LLM(如DeepSeek)读取注释和引用信息,并在EPUB中呈现。
LLM还能在一定程度上纠正OCR错误。
本地运行:
支持CPU和GPU加速,无需联网即可完成大部分操作。
PDF-Craft应用场景
学术研究:将扫描的学术论文转换为Markdown或EPUB格式,便于编辑和阅读。
电子书制作:将扫描书籍转换为EPUB格式,生成带目录和章节的电子书。
文档处理:提取PDF中的文字和图像,用于进一步编辑或归档。
")
PDF-Craft使用方法
1. 安装:需要Python 3.10及以上版本,支持CUDA加速。
2. PDF转Markdown:
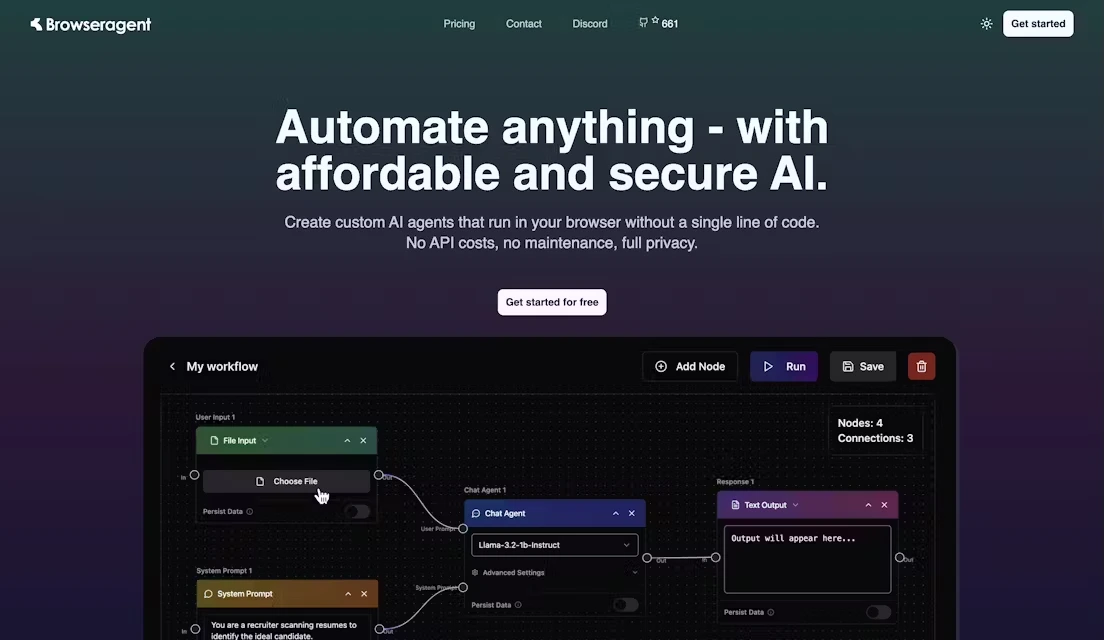
from pdf_craft import PDFPageExtractor, MarkDownWriter extractor = PDFPageExtractor(device="cpu", model_dir_path="/path/to/model") with MarkDownWriter(markdown_path, "images", "utf-8") as md: for block in extractor.extract(pdf="/path/to/pdf"): md.write(block)
3. PDF转EPUB:
from pdf_craft import PDFPageExtractor, LLM, analyse, generate_epub_file extractor = PDFPageExtractor(device="cpu", model_dir_path="/path/to/model") llm = LLM(key="sk-XXXXX", url="https://api.deepseek.com", model="deepseek-chat") analyse(llm=llm, pdf_page_extractor=extractor, pdf_path="/path/to/pdf", analysing_dir_path="/path/to/analysing", output_dir_path="/path/to/output") generate_epub_file(from_dir_path="/path/to/output", epub_file_path="/path/to/output.epub")
github项目:https://github.com/oomol-lab/pdf-craft