提交您的产品
提交您的产品  Ai应用
Ai应用 Ai资讯
Ai资讯 AI生图
AI生图 AI生视频
AI生视频 AI生PPT
AI生PPT AI数字人系统
AI数字人系统GPT-4.1、GPT-4.1 mini与GPT-4.1 nano的区别

Open ai以API 的形式推出了三个新模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。这些模型的性能全面超越 GPT-4o 和 GPT-4o mini,在编码和指令跟踪方面都有明显提升。它们还拥有更大的上下文窗口——支持多达 100 万个上下文标记——并且能够通过改进的长上下文理解更好地利用这些上下文,让我们看看它们之间有什么区别?
")
定位
GPT-4.1:作为GPT-4o的升级版,GPT-4.1在多模态能力(文本、图像、音频)基础上进一步优化,响应速度更快、推理深度更强,尤其在写作、编程和复杂问答场景中表现更自然,减少“答非所问”的情况。其上下文窗口支持1M tokens,最大输出32,768 tokens,并计划支持所有Copilot套餐。
GPT-4.1 mini:定位为中端轻量模型,专为边缘设备(如手机App、小程序)和轻量任务设计,牺牲部分性能以降低资源消耗,适合实时性要求高但算力有限的场景。与GPT-4o mini类似,其参数规模较小(约8B),但保留了核心多模态功能。
GPT-4.1 nano:是极致轻量化版本,专为移动端和嵌入式AI打造,参数规模更小(推测可能低于mini版本),强调低延迟和离线运行能力,例如在旧手机或无网络环境下仍可使用基础AI功能。
")
1. 模型大小与参数
GPT-4.1:完整的大型模型,拥有最多的参数,适合复杂任务和需要强大计算能力的场景。
GPT-4.1 mini:中等大小的模型,参数量较少,适合在资源受限的环境中使用,如普通的个人电脑或服务器。
GPT-4.1 nano:最小的模型,参数量最少,主要针对移动端和嵌入式设备等资源极其受限的场景。
2. 性能与效率
GPT-4.1:
在编码、指令遵循和长文本理解等任务上表现出色。
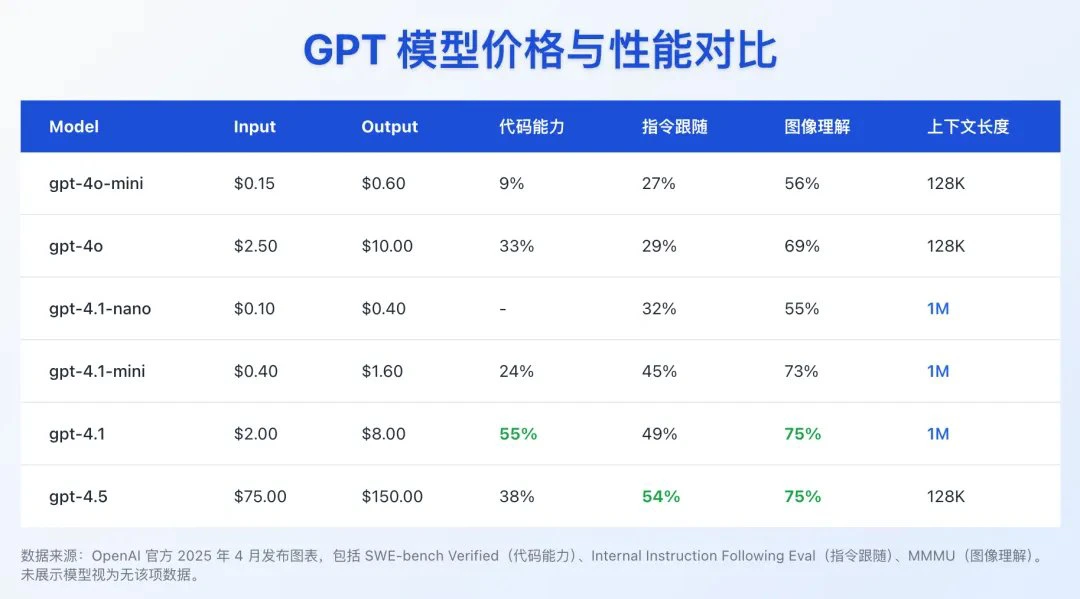
在 SWE-bench Verified 编码基准测试中得分为 54.6%,比 GPT-4o 提高了 21.4%。
在 Video-MME 长文本理解基准测试中得分为 72.0%,比 GPT-4o 提高了 6.7%。
GPT-4.1 mini:
在许多基准测试中表现接近甚至超过 GPT-4o,延迟降低了近一半,成本降低了 83%。
在 MMMU 图像理解基准测试中表现优异。
GPT-4.1 nano:
是最快的模型,延迟极低,通常在 128,000 输入 token 的查询中,首次返回 token 的时间不到五秒。
在 MMLU、GPQA 和 Aider polyglot coding 等任务上的表现甚至超过了 GPT-4o mini。
3. 适用场景
GPT-4.1:适用于需要强大计算能力和复杂任务处理的场景,如专业的软件开发、复杂的法律文档分析、大规模的数据处理等。
GPT-4.1 mini:适合在中端设备上运行,如普通的个人电脑、小型服务器等,可以处理一些中等复杂度的任务,如日常的文本生成、简单的编程辅助、图像理解等。
GPT-4.1 nano:主要针对移动端和嵌入式设备,如智能手机、平板电脑、智能家居设备等,适用于对响应速度要求高且资源受限的场景,如快速的文本分类、自动补全等。
4. 成本
| 模型 | 输入(每百万 token) | 缓存输入(每百万 token) | 输出(每百万 token) | 混合定价\*(每百万 token) |
|---|---|---|---|---|
| GPT-4.1 | $2.00 | $0.50 | $8.00 | $1.84 |
| GPT-4.1 mini | $0.40 | $0.10 | $1.60 | $0.42 |
| GPT-4.1 nano | $0.10 | $0.025 | $0.40 | $0.12 |
*基于典型的输入/输出和缓存比例。
5. 其他特点
长文本处理能力:
所有三个模型都支持 100 万 token 的上下文窗口,比之前的 GPT-4o 模型(12.8 万 token)大幅增加。
GPT-4.1 在长文本理解方面表现出色,能够更好地处理复杂的多文档任务。
指令遵循能力:
GPT-4.1 在指令遵循方面有显著提升,特别是在复杂的多轮对话中表现更好。
图像理解:
GPT-4.1 mini 在图像理解方面表现突出,通常优于 GPT-4o。
官方介绍:https://openai.com/index/gpt-4-1/